MAPLE: Modular Attention for Interpretable and Prosocial Multi-Agent Reinforcement Learning
{kind=link}
We propose a novel approach to enhance interpretability and performance in multi-agent reinforcement learning (MARL) through modular architecture and representation learning. We introduce MAPLE (Modular Attention for Prosocial Learning), a MARL architecture built on Independent Proximal Policy Optimization (IPPO) with brain-inspired modular processing that mirrors the functional specialization observed in human neural systems.
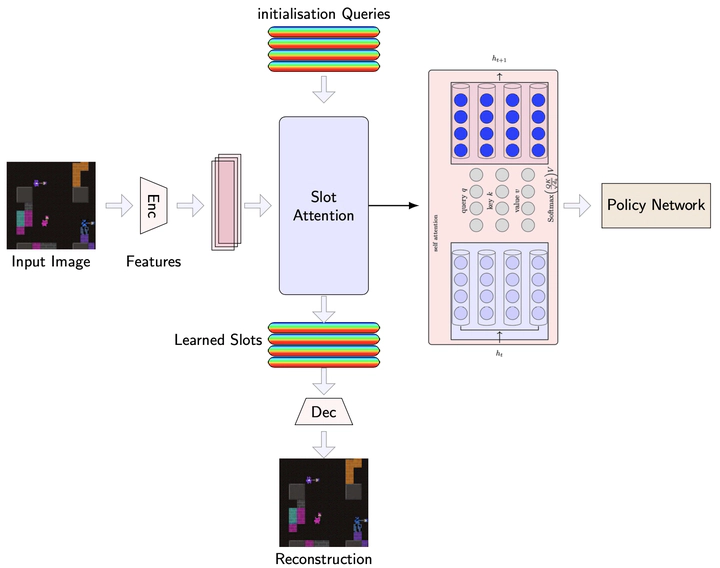
We incorporate a pre-trained slot attention model to learn compositional, object-centric representations, along with modular recurrent networks that interact through an attention bottleneck, consistently outperforming end-to-end RL across different environments. Our architecture incorporates three key mechanisms to address challenges in complex social scenarios:
- Learning orthogonal latent representations and directing them through modular recurrent neural networks, allowing different modules to specialize in processing distinct environmental features.
- Enabling generalization via compositional consistency loss for slot attention modules.
- Using different fine-tuning approaches such as LoRA and progressively unfreezing parts of the slot attention module during RL training, allowing pretrained representations to adapt while maintaining their specialized structure.
Moreover, we integrate modular Recurrent Independent Mechanisms (RIMs) in agents’ value networks, encouraging sparsity and fast adaptation to changing environments, with modules dynamically activating based on relevant environmental contexts. This unique combination of attention mechanisms and modular processing results in specialized neural components that focus on different environmental aspects, thus improving coordination, generalization, and interpretability.
We evaluate MAPLE in DeepMind’s Melting Pot suite across three environments: mixed strategies (Prisoner’s Dilemma), social good (Allelopathic Harvest), and resource management (Territory Room). Our results demonstrate that MAPLE not only enhances performance but also reveals emergent social capabilities across environments while providing deeper insights into the learned representations driving agent behaviors.